9 Best Practices for writing CloudFormation custom resources
This article is written for infrastructure coders (and those who aspire to become one) using CloudFormation to define their infrastructure. It focuses on CloudFormation custom resources feature, which expands beyond what Amazon offers by default. Points below are knowledge extract of issues that were repeatedly revealed during my infrastructure coding and automation journey. These are mix of applied good code coding principles (“return meaningful errors”) and devops principles (“fail fast, fail early”)
Content is accompanied by GitHub repository demonstrating different aspects of points discussed below.
Some basics
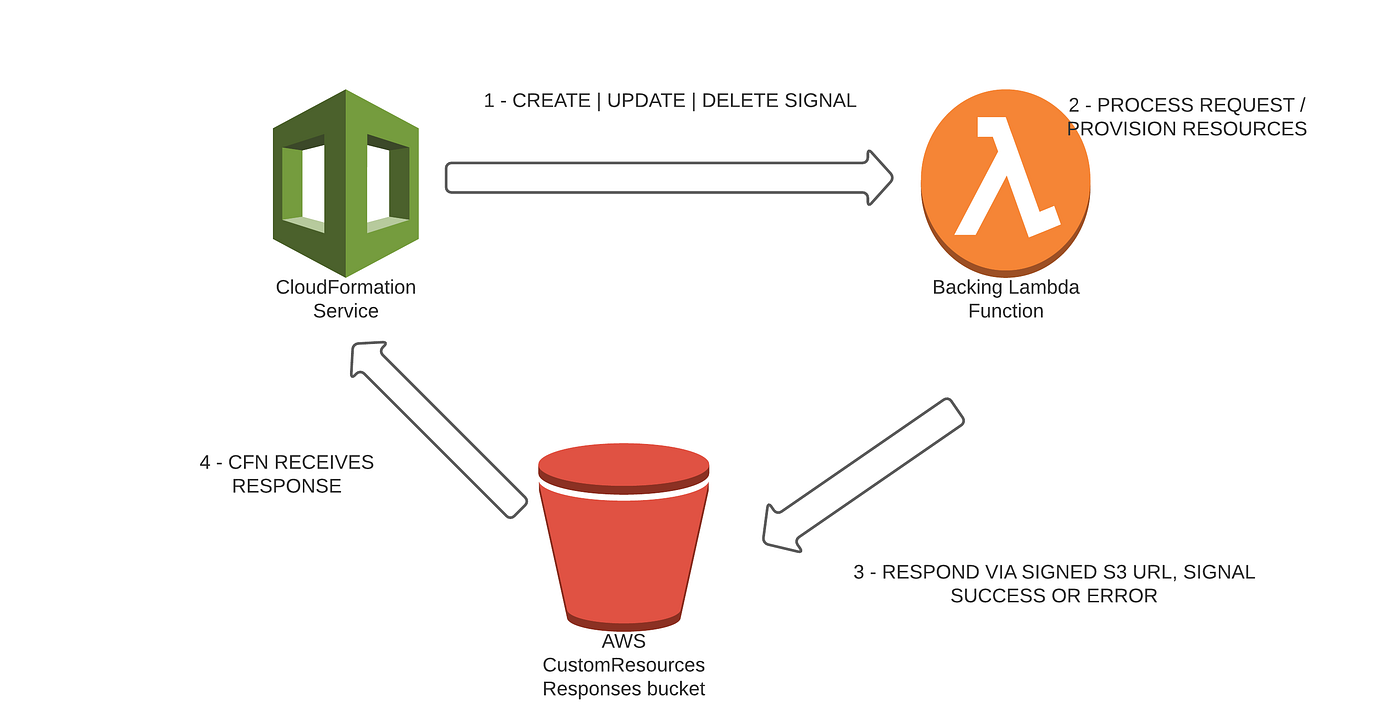
CloudFormation custom resources are AWS mechanism allowing to execute arbitrary code in stack lifecycle, initially backed by SNS Topics, with AWS Lambda functions being backing implementation mechanism for most of them nowadays. All of the points below will use AWS Lambda as backing mechanism, and Python 3 as implementation programming language. As part of regular lifecycle, custom resources go through different stages of CREATION, UPDATES, and DELETION, and as described in the points below it is crucial to understand when and why these signals are being sent to Lambda Function by CloudFormation service. Under the hood, custom resources are using s3 signed urls for communication back with CloudFormation service, as depicted on diagram below.
Best practices
Code snippets and examples below are implementing custom resource which creates / updates / removes S3 object with arbitrary content
Example of S3 object custom resource consumption from within CFN template
MyS3Object:
Type: Custom::S3Object
Properties:
ServiceToken: !GetAtt CustomResourceLambda.Arn
Bucket: !Ref BucketName
Object: blog_article.txt
Content: >
This content is generated using CloudFormation custom resource1 — Create the stack without custom resource initially
I’ve had this one listed as last point, but it moved to #1 after realising how important it is. It is time saver in the testing phase of the custom resource. Consider creating custom resource that is in the same stack as 1TB Microsoft SQL Server RDS database resource, and depends on it. You’ll wait for 45 minutes for DB to create ( it may be exaggeration, but useful one to illustrate a point), only to find out your custom resource failed and stack rolled back. Do this 8 times a day, and you’ll have a good standup status update for the team — “Troubleshooting errors in the custom code”. Or you could subject your custom resource to parameter-bound CFN condition and deploy the stack WITHOUT the custom resource initially, and allow it to fail fast and early.
2 — Abstract away response comms
This rule could also be called “basics of writing modular code”. Whatever paradigm of your language of choice is, be it object oriented, functional or procedural — create abstraction layer to communicate back to CloudFormation. This way your custom resource main routine is more readable and has single line saying “signal success” or “signal error”. Example below is simple Python class, that accepts CFN lambda payload in initialize (constructor) method, and has error and success methods. Additionally, AWS offer cfn-response module in case you are using ZipFile property to define Lambda function code inline.
3— Log incoming payload
For debugging and tracing purposes, you’ll always want incoming payload message from CloudFormation logged in functions CloudWatch log group. Not only it helps to understand the message structure (or you can read the spec), but also, if printed as json string, it can be used as a payload to directly invoke backing lambda function during manual testing process. Ensuring that IAM Role used by Lambda function has permissions to write to CloudWatch, by Amazon-provided AWSLambdaBasicExecutionRole managed policy before lambda is deployed will help you skip another common beginner pitfall.
Add simple stdout print to beginning of custom resource routine
4 — Choose good physical ids.
PhysicalResourceId field that is required by CloudFormation response specification should communicate unique identifier for resource being created. It is generally good idea to create helper routine to generate resource id based on passed in resource properties. Points 6 and 7 below illustrate possible problems if physical id is not chosen appropriately. As a rule of the thumb, think of which properties change PhysicalResourceId — comparing to AWS CloudFormation resources, think of resource properties which require replacement when updated.
5 — Always catch and report on errors
“custom resource failed to stabilize in expected time” — this is not the error message you want to see after staring at the CloudFormation web console, clicking “refresh events” button for several minutes. This should really be the basics for any code your write, not a particularity of cloud engineering. However, the feedback loop (time you fiddle the thumbs waiting to see the output your code produces) can be significantly increased compared to seeing simple syntax error when testing local workstation script. Wrap all of your code in try/catch loop, and report errors back to CloudFormation service if and when they happen.
6 — Design for prior existence of created resource
Consider following situation — you work on a software application project with multiple dev stacks (each developer has their own), with shared physical data layer. You create custom resource that populates the database with some sample data. If you do not cater for prior existence of this data, your custom resource may fail with database “duplicate key” error, creating potential race condition between different stacks, though you just may want for it to continue in case of the data being already present. Depending on the context of the custom resource, desired behaviour in such situation may either be to fail or continue the stack creation. Either way, your code should handle it. If requirements are such that existing object should be ignored (or overwritten), CREATE and UPDATE request types are often handled via the same routine.
7 — Consider UPDATE → DELETE invocation cycle
There are some cases where change of resource input parameters will result in creation of the new physical resource (e.g. custom resource accepts path and bucket for an S3 object). Rather than explicitly deleting the custom resource in within the UPDATE execution path, respond with different PhysicalResourceId to CloudFormation. Once CFN service receives new value for the actual resource identifier, it will send another request with DELETE as value of RequestType . In other words, handle updates for {RequestType=UPDATE} , handle deletes for {RequestType=DELETE} , and make sure that you follow rule 4 above, pick good values for PhysicalResourceId
8 — Consider CREATE → CANCEL lifecycle path
Another oversight that can lead to staring into DELETE IN PROGRESS resource status within CFN console is not factoring in user-initiated stack creation cancellation in your code. This rule is closely related to rule 6 above, with a twist that you should plan for lack of the existence of the resource in DELETE execution path. If your custom resource receives DELETE signal, before completing it’s CREATE cycle, it may end up failing due attempt of removal of object that wasn’t there in the first place. One way to protect from such race condition is limiting backing Lambda function concurrency to 1 (effectively serializing all requested executions), so the Lambda function invocation for DELETE won’t be triggered until CREATE request has been completed. But even then, creation may not complete successfully as dependant resources are removed during stack deletion — e.g. bucket where you’d write an data object using custom resource is removed, as operations staff has cancelled the stack creation. While this situation may not apply to all of the use cases, it’s something that can cause issue down the line.
9 — Expose useful resource properties
CR Response object specification allows for list of key-value pairs defined within Data key. To allow custom resource to be used across different stacks, templates and situations, consider what are the useful attributes that CFN infrastructure coder may use. In case of the S3 object custom resource it may be StorageClass, specified in x-amz-storage-class header, or object canned acl. This properties are available for consumption by other resources within the template via intrinsic Fn::GetAtt function. Also, make sure to use NoEcho key if you are sending any sensitive information back to the CFN service.
As a closing note, advice is not take the list above as “checklist for building CFN custom resources”, but rather accumulated knowledge of common pitfalls and good practices.